ÚČNK FF UK udržuje několik databází češtiny a hromadu nástrojů k jejich využití. Máte k dispozici podstatně upravený výcuc z databáze SYN2010 (v podstatě tuším výběr slov z novinových článků za jisté časové období), a to konkrétně jeho ASCII-podobu, tedy sice česká slova, ale bez háčků, čárek a dalších nabodeníček.
V poslední úloze budete potřebovat slova z tohoto slovníku v kapitalizované podobě (tedy např. jako ZVLASTNI), připravte si je proto tak. Přitom odpovězte na následující otázky:
PS: Pro vyřešení poslední úlohy vám sice stačí seznam slov zbavený duplikátů, ale následující úloha vám může řešení značně usnadnit.
Jak už jste zjistili v předchozí úloze, korpus SYN2010 obsahuje hromadu duplikátů. V této úloze máte za úkol zjistit rozložení počtu slov podle délky a rozdíl po započítání duplikátů. Konkrétně:
Graf – pro relevantní část vstupních dat – by měl vypadat asi takto (z pochopitelných důvodů bez popisek :-):
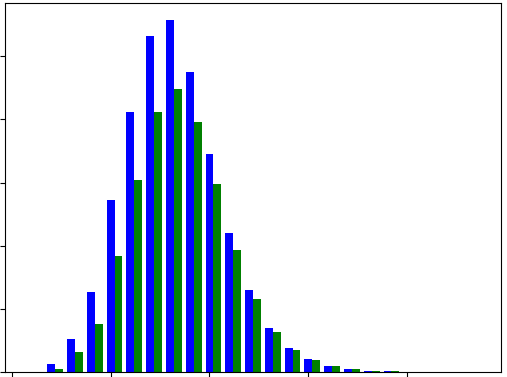
Modře jsou celkové počty slov příslušné délky, zeleně pak totéž bez duplikátů.
Vigenèrova šifru jest variantou Césarovy šifry – také dochází k posunu písmen, ale tento posun není určen pouze jedním vybraným číslem (a tedy vlastně písmenem), nýbrž celým klíčovým slovem (heslem) nebo dokonce delším textem. Po sobě jdoucí písmena původní zprávy jsou tedy vlastně šifrována Césarovými šiframi s různým krokem. Příklad s heslem HESLO:
| zpráva: | PYTHON JE FAJN |
|---|---|
| heslo: | HESLOH ES LOHE |
| výstup: | WCLSCU NW QOQR |
Vysvětlení: První písmeno P je zašifrováno posuvem určeným prvním písmenem hesla, tj. písmenem H. Jelikož písmeno H značí posun od písmene A o 7 znaků, je v tomto případě písmeno P zašifrováno jako W. (Jestli by to nemělo být spíš X je otázka :-) Pokud při posunu dorazíte na konec abecedy, cyklicky přejdete na její začátek a počítáte dál.
Máte k dispozici následující text zašifrovaný Vigènerovou šifrou s neznámým heslem. Jedná se o český text, pro zjednodušení ale beze všech nabodeníček (tedy je v ASCII). Jako heslo bylo použito jedno ze slov z korpusu SYN2010, ale nevíte které. Vaším úkolem je zjistit použité heslo a text rozšifrovat.
Kdo vyřešil předchozí úlohu, má k dispozici nápovědu, která mu výrazně omezí počet hesel k vyzkoušení: Heslo pochází ze slov dané délky, pro které je největší počet duplikátů a ještě navíc je samo duplikátem.
Vzhledem k počtu možností (celkově několik set tisíc a i s nápovědou je to pořád v řádech tisíců!) se rozumí samo sebou, že kandidáty na hesla nebudete hledat ručně, ale přijdete s nějakým vtipným řešením jak poznat, že rozkódovaný text by mohl být v ASCII-čestině (tedy cestine).
PS: Vřele doporučuji nejdříve odladit algoritmus na velmi omezené podmnožině slov (třeba jen deset) a teprve po ověření jeho správnosti ho pustit na všechna.